The foundations
80% of all data within an organization is dark data, IBM concluded in a study in 2018 which predicted that this volume would grow to a gigantic 93% in 2020. How much unused data does your company mean to no avail?
In this blog, we dive deeper into the dark data and look at how this ballast can be transformed into meaningful, transparent data that can help to have the right information available at the right time:
- From dark to smart data – the foundations
- Structure your data with SharePoint Syntex
- The extra mile – the Spikes tagging framework
How does dark data arise?
Files that were first actively used, even intensively, turn into dark data when nothing is done with them, at the end of a project, a personnel or structure change. The files are kept, but then nothing is done with them for so long that people forget they are there.
We often also see files being saved multiple times unnecessarily. Many causes are at the root of this phenomenon:
- The information is not found quickly enough and therefore downloaded again
- The structure in which the information resides is unclear, which causes duplications
- Documents are shared and re-saved via email
- …
These habits ensure that the amount of dark data only increases. The result: the volume of outdated, redundant or invisible information increases explosively.
Smart data generator
However, don’t be fooled, there is nothing “dark” about this data. On the contrary, it actually has potential! The key is to extract knowledge from this dark data. After structuring these documents, the information is easily retrievable, applicable and smart.
That is, of course, put simply. If more than 80% of your data consists of unstructured information, then any help in structuring it is more than welcome. Fortunately, techniques such as Artificial Intelligence and in particular Natural Language Processing take up this often incalculable task for you.
The smart data generator is a pipeline that records "dark data", processes it and, as the end result, makes the extracted information available again together with the unstructured information.
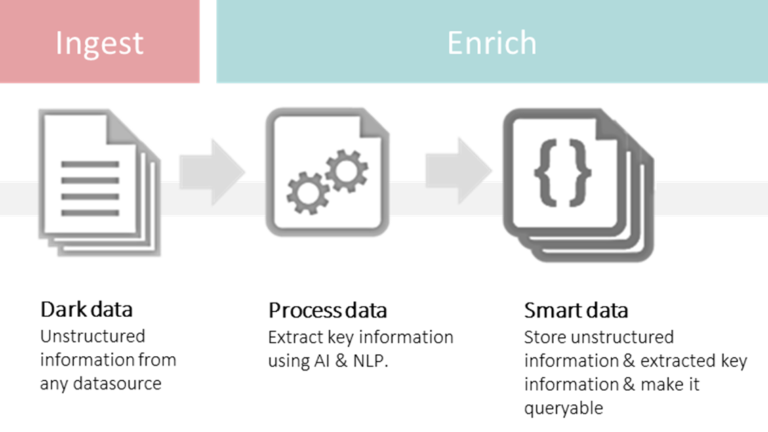
The smart data generator pipeline can be set up in various ways. The most appropriate candidate to help convert from dark to smart is the search engine. A search engine has been created to find information through its connection to various data sources. Via extensions, the operation is adapted to the specific needs of your organization. If your company already has a search solution, the foundation of the ‘smart data generator’ has already been laid.
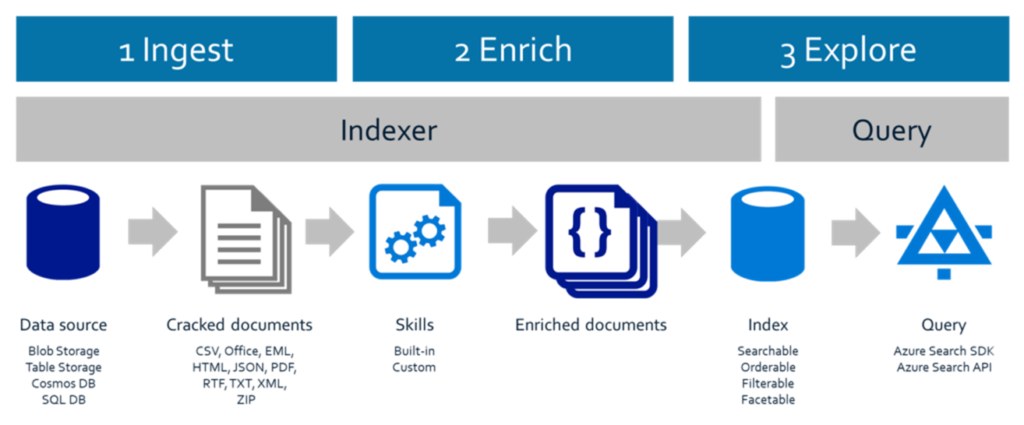
Figure 1 – The above image shows how Azure Search, like many other search solutions, can be extended with extra “skills” to extract meaningful information from a document and include it as an “enriched document” in the search index.
Are these standard search solutions not enough to make all data smart? Unfortunately, this is not that easy. Search engines are extremely powerful, but also require follow-up and adjustment. We often forget that behind “Google” is a massive team that constantly monitors trends, adjusts algorithms and analyzes usage data to provide the best search experience (see https://www.searchenginejournal.com/google-algorithm-history/). An out-of-the-box search engine on top of a gigantic mountain of documents performs poorly: an abundance of results without options for refinement means a waste of time and manual scanning of information.
A document management system is a second option. An extension allows you to attach additional information such as tags and metadata to a document. When uploading a new or modified document, the extracted tags are also saved.
Figure 2 – The above animation shows a document library where the metadata are attached to the documents in an automated manner and without the intervention of the end user, in order to offer a much richer filtering and search options.
Such a Smart Data Generator such as SharePoint Syntex, the latest add-on from Microsoft 365, is available for every use case and even for a limited budget. Further in this article, we look at the practical implementation of these and other smart data generators for the design of intelligent digital workplaces.
Structure your data
Transforming dark data into smart data is not black magic and thanks to the latest developments, the technology required to generate structured information from scratch is even very accessible. In this section we take a closer look at SharePoint Syntex, the Microsoft version of a Smart Data generator.
SharePoint Syntex
With the expansion of the content services in M365, Microsoft has recently also fully focused on intelligent enrichment. The new showpiece has been given the name “SharePoint Syntex” and should help companies to convert unstructured information into smart data.
SharePoint Syntex is available as an add-on for E3 and E5 licenses at $ 5 / user / month. To do this, you plug a data pipeline into your Office 365 platform that cleverly combines various AI techniques with the expertise of your knowledge experts. With this technique, called machine teaching, it becomes possible to achieve an accurate result with minimal training. This is in contrast to many AI applications that are very training intensive.
The image below provides an overview of the AI techniques that SharePoint Syntex offers for different types of information. Let’s go through the different possibilities!

Figure 3 – SharePoint Syntex uses different techniques to generate metadata from different types of documents.
Object detection – generate tags for your images
An image says more than a thousand words, so I am not going to venture into a detailed explanation and let the example below speak for itself. Object detection detects and names objects in images. This way images become searchable with a standard search engine. A time-saving application if you need to search an image bank for the most suitable image for your news articles.

Would you like to test this out on your own image? Surf to Microsoft’s demo site and be amazed by the results! This technique is ingrained in SharePoint Syntex and requires no manual training. Ready for use!
Forms Processing – data from semi-structured information
Specifically for semi-structured documents such as forms, tables and key-value based information, Microsoft has incorporated an AI-based technique in SharePoint Syntex that, with the help of your knowledge experts, extracts information from the documents that is of interest. It proceeds as follows:
- Uploads at least 5 documents of the same type
- SharePoint Syntex gets to work and searches for all semi-structured information
- In the last step you indicate which information you find important and how you want to store it
With this information, SharePoint Syntex is able to successfully process and structure similar documents. It couldn’t be easier!
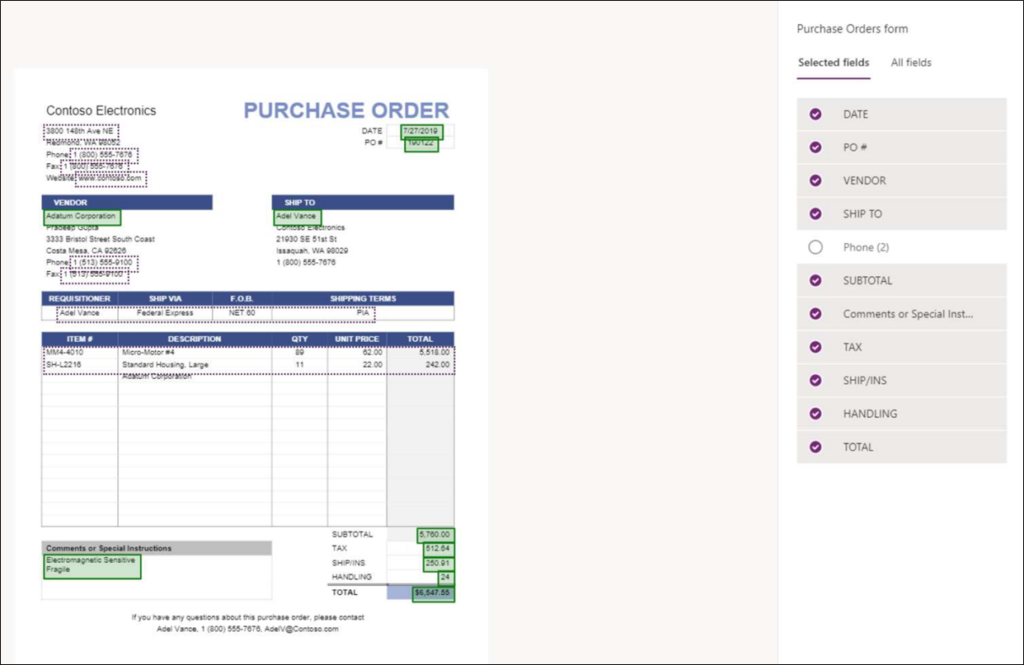
Figure 4 – Forms Processing offers an interface to indicate the found semi-structured information you want to use so that other similar documents are processed in the same way.
The result: your invoices neatly arranged per customer, sorted by purchase amount, grouped by VAT number or simply searchable by the information you have extracted from the documents.
File classification & entity extraction – unstructured information by the merry-go-round
The latest and most advanced application of Machine Teaching is file classification & entity extraction. Just like with Forms recogniser, you can upload 5 documents as an example of a type of document, for example a contract. Unlike forms, this often involves text without structure, such as tables. In order to extract information from this, a push from your knowledge workers is needed. Often the information is recognizable by the way it is included in the document: an amount based on the dollar sign, parties involved by the wording, other elements based on their location in the text. By explicitly including these rules as “Explanation”, the technique is able to learn from a minimal set of examples and extract the information from the document.
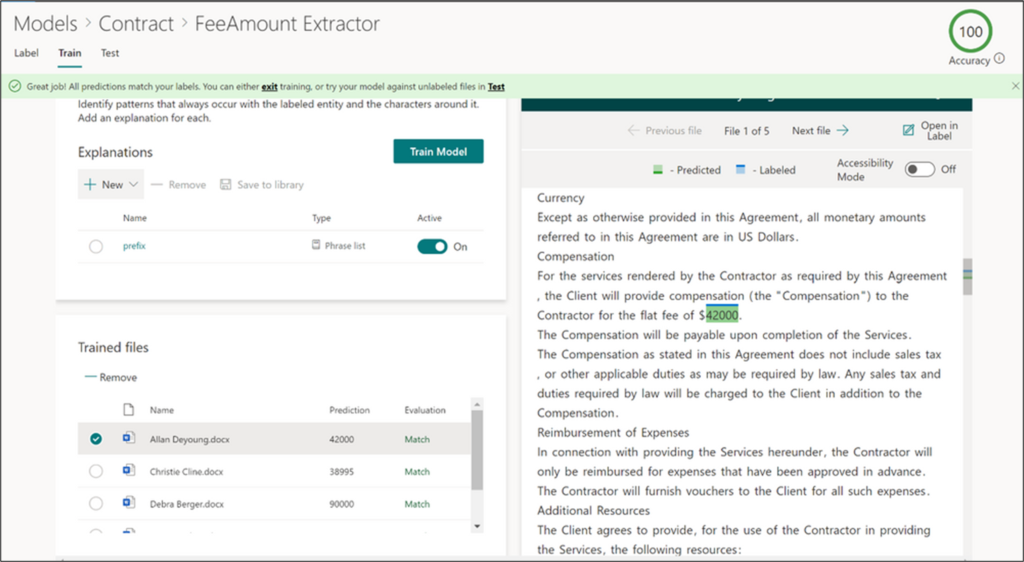
Figure 5 – Based on a minimal set of training documents and some ‘explanations’ from your knowledge workers, SharePoint Syntex is able to extract information from documents.
Is SharePoint Syntex the holy grail?
Probably not. Information is often contained in documents contextually and is therefore more difficult to comprehend in lines. It requires expertise in a domain to see the knowledge. In addition, language support for SharePoint Syntex is limited to English for now. However, Microsoft is clearly on the “democratized AI” path and will undoubtedly continue to develop SharePoint Syntex into a widely usable product. Despite these limitations, we can already cover quite a few use cases through technology today.
In the last part, we take a closer look at the Spikes tagging framework. A generic component that Spikes has already used successfully with various customers to capture more contextual information in different languages.
The extra mile – Spikes tagging framework
Like Microsoft, Spikes has embarked on the path of intelligent, smart collaboration and developed a framework with a similar objective: structuring documents to make them easily searchable and usable for various knowledge-supported processes. This solution is open by nature and extensible, which means that a wide range of documents have been successfully processed in different industries. In addition, the framework offers support in multiple languages including Dutch, French and English.
In addition to the usual pre-trained AI algorithms such as sentiment analysis, topic mining, etc., the platform also has expansion options to apply highly specialized AI algorithms or own AI models available on the market. In addition, the system can be integrated with different data sources and can also deliver the processed data to different platforms.
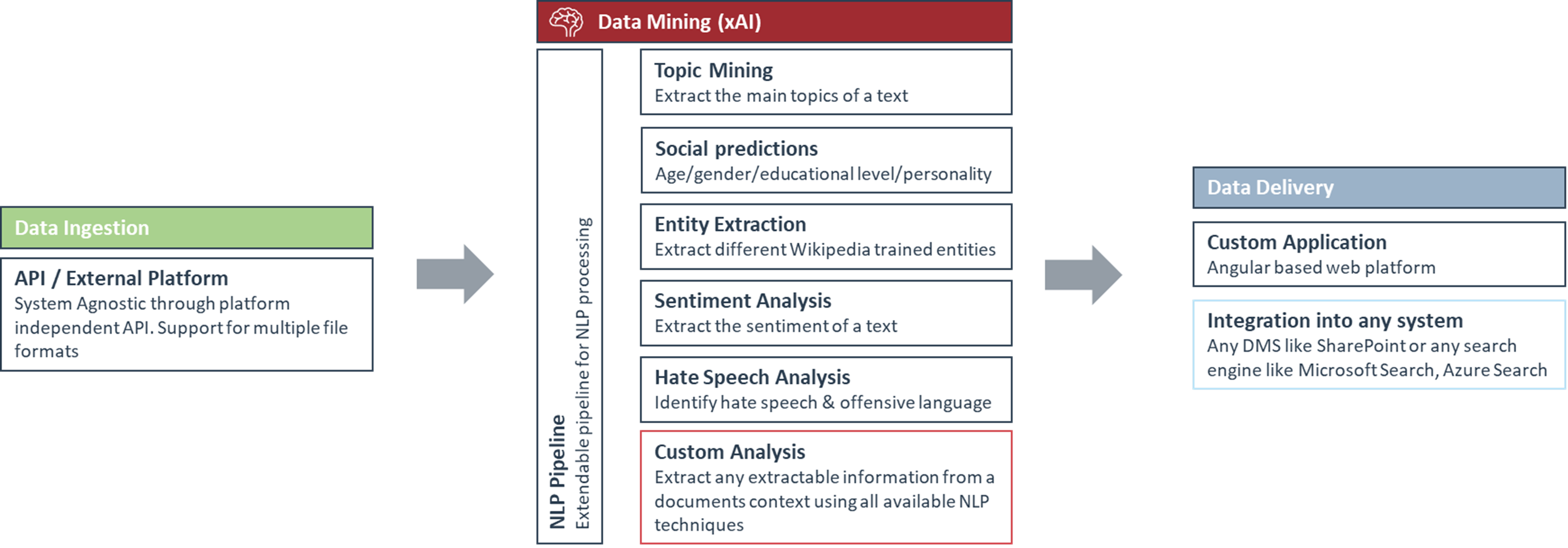
Figure 6 – The above image shows the tagging pipeline that Spikes sets up to analyze and structure unstructured documents based on every available AI technique.
We would like to demonstrate that the framework covers an enormously diverse set of use cases with a few examples of successful implementations.
- Searchable recipes: For a global player in the industrial bakery with various local branches, we installed the tagging framework to recognize not only ingredients but also own product names, locations, applications (dough, topping,…),…. In addition, the recipes were also automatically classified as gluten or gluten-free.
- Automatic provision of relevant research: when extracting raw materials in mines, an enormous number of different processes and techniques are used on different materials. The research that appears worldwide in this regard is therefore very extensive and diverse. In order not to overload researchers with information, but to offer them relevant knowledge, the research papers were automatically analyzed and processes, chemical components and techniques were extracted from the documents.
Due to the open implementation of the platform, we are also not tied to one fixed platform. Once the knowledge has been successfully unlocked, all options are open, including SharePoint where the documents are provided with extra tags, bots that use Azure search in, for example, Teams, own applications & mobile applications.
Of course, the dark data that has been converted into more structured information will only be profitable if it is also used smartly. Only then will they deliver on the promise of ‘smart’ data. In the blog series “The right information at the right time” we go deeper into the contextual provision and application of knowledge at the right time.
Smart applications to get people to work together with enthusiasm is in our DNA. If you have any questions or would like to submit your own use case, do not hesitate to contact us!

Ben Van Mol
Solution Architect
Curious about the various options for organizing knowledge within your organization? Don’t miss the webinar about automated knowledge bear on October 20 and register soon.
More information and registration can be done via the yellow button below.

