De fundamenten
80% van alle data in een organisatie is dark data, zo concludeerde IBM in 2018 in een studie die voorspelde dat dit volume zou groeien naar een gigantische 93% in 2020. Hoeveel ongebruikte data verzwaart ondertussen zonder enig nut jouw bedrijf?
In deze blog duiken we dieper in de dark data en bekijken we hoe deze ballast omgetoverd kan worden in zinvolle, transparante data die kunnen helpen om de juiste informatie op het juiste moment ter beschikking te hebben:
- Van dark naar smart data – de fundamenten
- Structuur in je data met SharePoint Syntex
- De extra mile – het Spikes tagging framework
Hoe ontstaan dark data?
Bestanden die eerst actief, zelfs intensief, gebruikt werden veranderen in dark data wanneer er niets meer mee gedaan wordt, bij het einde van een project, een personeels- of structuurwissel. De bestanden blijven bewaard, maar vervolgens wordt er zo lang niets meer mee gedaan dat men vergeet dat ze er zijn.
Vaak zien we ook dat bestanden onnodig meerdere keren worden opgeslagen. Aan de basis van dit fenomeen liggen vele oorzaken:
- De informatie wordt niet snel genoeg gevonden en daarom maar opnieuw gedownload
- De structuur waarin de informatie zit is onduidelijk waardoor dubbels ontstaan
- Documenten worden via mail gedeeld en opnieuw opgeslagen
- …
Deze gewoontes zorgen ervoor dat de hoeveelheid dark data alleen maar groter wordt. Het gevolg: het volume verouderde, overbodige of onzichtbare informatie neemt explosief toe.
Smart data generator
Laat je echter niet misleiden, er is niets ‘dark’ aan deze data. Integendeel, er zit juist potentieel in! De sleutel zit in het extraheren van kennis uit deze dark data. Na het structureren van deze documenten is de informatie vlot opvraagbaar, toepasbaar en smart.
Dat is natuurlijk eenvoudig gezegd. Als meer dan 80% van jouw data uit ongestructureerde informatie bestaat, dan is elke hulp bij het structureren ervan meer dan welkom. Gelukkig nemen technieken zoals Artificiële Intelligentie en in het bijzonder Natural Language Processing deze vaak niet te overziene taak voor jou op.
De smart data generator is een pipeline die ‘dark data’ opneemt, verwerkt en als eindresultaat de geëxtraheerde informatie samen met de ongestructureerde informatie weer beschikbaar maakt.
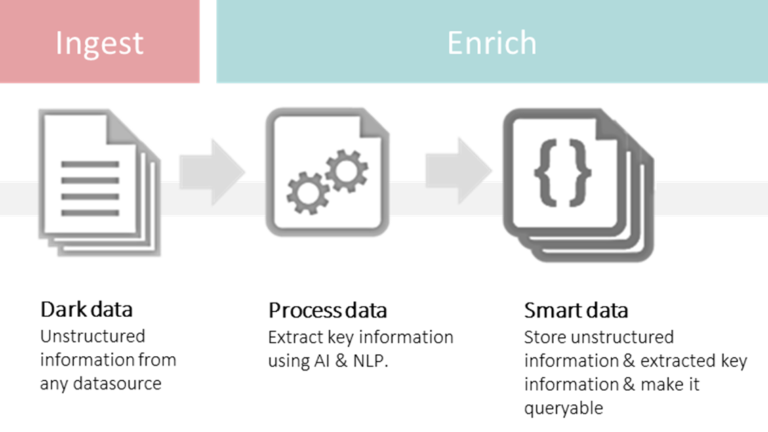
De smart data generator pipeline kan op verschillende manieren opgezet worden. De meest aangewezen kandidaat om te helpen bij het omzetten van dark naar smart is de zoekmotor. Een zoekmotor is gemaakt om informatie terug te vinden via zijn connectie met verschillende databronnen. Via uitbreidingen wordt de werking aangepast aan de specifiek noden van jouw organisatie. Beschikt jouw bedrijf al over een zoekoplossing, dan is het fundament van de ‘smart data generator’ alvast gelegd.
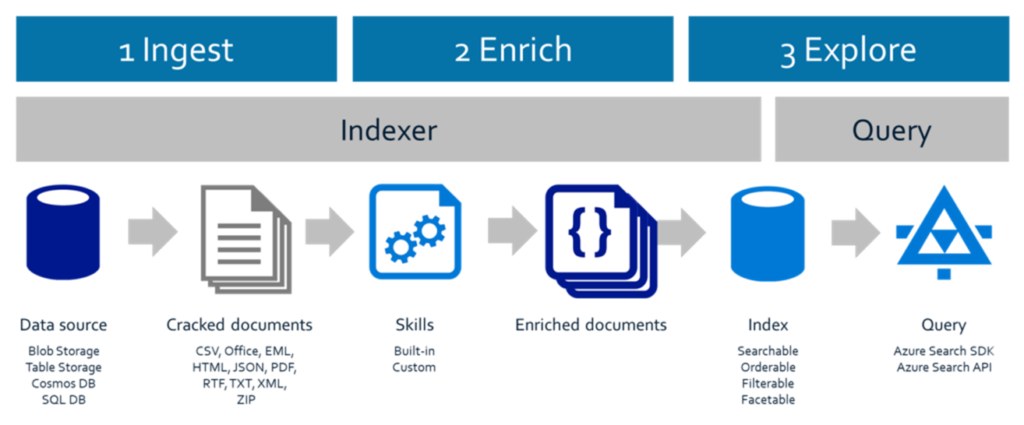
Figuur 1 – Bovenstaande afbeelding toont hoe Azure Search net zoals vele andere zoekoplossingen uitgebreid kan worden met extra ‘skills’ om uit een document zinvolle informatie te trekken en als ‘enriched document’ in de zoekindex op te nemen.
Volstaan die standaard zoekoplossingen dan niet om alle data smart te maken? Helaas is dit niet zo eenvoudig. Zoekmotoren zijn enorm krachtig maar vereisen ook opvolging en aanpassing. We vergeten vaak dat achter ‘Google’ een gigantisch team zit dat constant trends opvolgt, algoritmes aanpast en gebruiksdata analyseert om de beste zoekervaring te bieden (zie https://www.searchenginejournal.com/google-algorithm-history/). Een out-of-the-box zoekmotor bovenop een gigantische berg documenten presteert matig: een overvloed aan resultaten zonder optie tot verfijning betekent tijdsverlies en manueel scannen van informatie.
Een document beheer systeem is een tweede optie. Een uitbreiding staat toe om extra informatie als tags en metadata aan een document te hangen. Bij het opladen van een nieuw of gewijzigd document worden de geëxtraheerde tags mee opgeslagen.
Figuur 2 – Bovenstaande animatie toont een document bibliotheek waar de metadata op een geautomatiseerde manier en zonder tussenkomst van de eindgebruiker aan de documenten worden opgehangen om zo een veel rijkere filtering en zoekmogelijkheden aan te bieden.
Zo’n Smart Data Generator zoals SharePoint Syntex, de laatste nieuwe add-on van Microsoft 365, is voor iedere use case en zelfs voor een beperkt budget beschikbaar. Verder in dit artikel, kijken we naar de praktische implementatie van deze en andere smart data generatoren voor de inrichting van intelligente digitale werkplekken.
Structuur in je data
Dark data omvormen tot smart data is geen zwarte magie en dankzij de laatste ontwikkelingen is de technologie die nodig is om uit het niets gestructureerde informatie te genereren, zelfs zeer bereikbaar. In dit onderdeel gaan we dieper in op SharePoint Syntex, de Microsoft versie van een Smart Data generator.
SharePoint Syntex
Met de uitbreiding van de content services in M365 trekt Microsoft sinds kort ook voluit de kaart van de intelligente verrijking. Het nieuwe paradepaardje heeft de naam ‘SharePoint Syntex’ meegekregen en moet bedrijven helpen om ongestructureerde informatie om te zetten in smart data.
SharePoint Syntex is beschikbaar als add-on voor E3 en E5 licenties aan 5$/gebruiker/maand. Hiervoor plug je een data pipeline in je Office 365 platform die verschillende AI technieken slim combineert met de expertise van jouw kennisexperten. Met deze techniek, machine teaching genoemd, wordt het mogelijk om met minimale training tot een accuraat resultaat te komen. Dit in tegenstelling tot veel AI toepassingen die erg trainingsintensief zijn.
Onderstaande afbeelding geeft een overzicht van de AI technieken die SharePoint Syntex aanbiedt voor verschillende types informatie. Laten we eens door de verschillende mogelijkheden gaan!

Figuur 3 – SharePoint Syntex gebruikt verschillende technieken om metadata uit verschillende types documenten te genereren.
Object detection – genereer tags voor je afbeeldingen
Een afbeelding zegt meer dan duizend woorden, ik ga me dan ook niet wagen aan een gedetailleerde uitleg en onderstaand voorbeeld voor zichzelf laten spreken. Object detection ontdekt objecten in afbeeldingen en benoemt ze. Zo worden afbeeldingen doorzoekbaar met een standaard zoekmotor. Een tijdsbesparende toepassing als je een beeldenbank moet doorzoeken op de best passende afbeelding voor jouw nieuwsartikels.

Wil je dit eens uittesten op een eigen afbeelding ? Surf naar de demo site van Microsoft en laat je verbluffen door de resultaten! Deze techniek zit ingebakken in SharePoint Syntex en vereist geen manuele training. Klaar voor gebruik!
Forms Processing – data uit semi-gestructureerde informatie
Specifiek voor semi-gestructureerde documenten als formulieren, tabellen en key-value based informatie heeft Microsoft een AI-gebaseerde techniek in SharePoint Syntex ingewerkt die met de hulp van jouw kennisexperten die informatie uit de documenten haalt die interessant is. Het gaat als volgt te werk:
- Laadt minimaal 5 documenten van een zelfde type op.
- SharePoint Syntex gaat aan de slag en gaat op zoek naar alle semi-gestructureerde informatie
- In de laatste stap duid je aan welke informatie je belangrijk vindt en hoe je deze wil opslaan
Met deze informatie is SharePoint Syntex in staat om gelijkaardige documenten succesvol te verwerken en te structureren. Eenvoudiger kan niet!
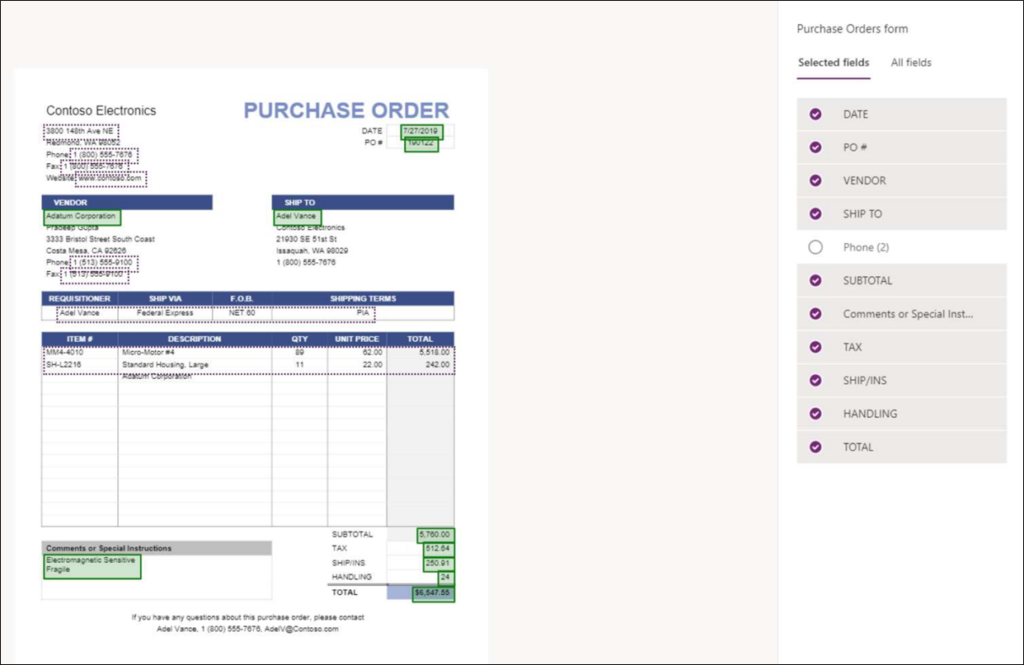
Figuur 4 – Forms Processing biedt een interface ter beschikking om de gevonden semi-gestructureerde informatie die je wil gebruiken aan te duiden zodat andere gelijkaardige documenten op dezelfde manier verwerkt worden.
Het resultaat: je facturen netjes gerangschikt per klant, gesorteerd volgens aankoopbedrag, gegroepeerd op BTW nummer of gewoon eenvoudig doorzoekbaar op de informatie die je uit de documenten gehaald hebt.
File classification & entity extraction – ongestructureerde informatie door de draaimolen
De laatste en meest geavanceerde toepassing van ‘Machine Teaching’ is file classification & entity extraction. Net als bij Forms recogniser laad je 5 documenten op als voorbeeld van een type document, bijvoorbeeld een contract. In tegenstelling tot formulieren gaat het hier vaak om tekst zonder structuur zoals tabellen. Om hieruit toch informatie te trekken, is een duwtje van jouw kenniswerkers nodig. Vaak is de informatie herkenbaar door de manier waarop ze is opgenomen in het document: een bedrag op basis van het dollar teken, betrokken partijen door de formulering, andere elementen op basis van hun locatie in de tekst. Door deze regeltjes expliciet op te nemen als ‘Explanation’ is de techniek in staat om aan de hand van een minimale set aan voorbeelden te leren en de informatie goed te onttrekken uit het document.
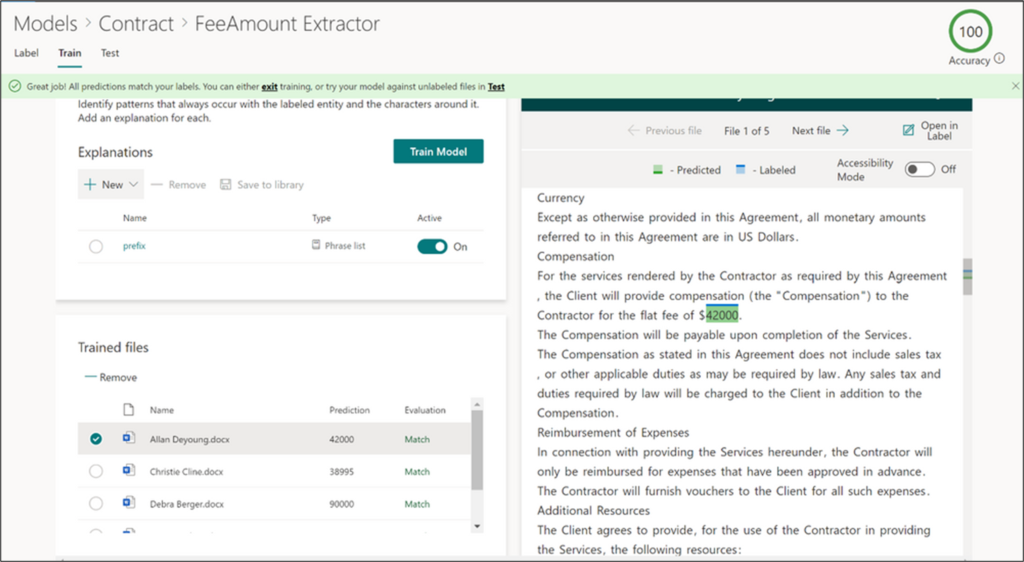
Figuur 5 – Aan de hand van een minimale set trainingsdocumenten en enkele ‘explanations’ van je kenniswerkers, is SharePoint Syntex in staat informatie te onttrekken uit documenten.
Is SharePoint Syntex de holy grail?
Waarschijnlijk niet. Informatie zit vaak contextueel vervat in documenten en is daardoor moeilijker in regeltjes te vatten. Het vereist expertise in een domein om de kennis te zien. Bovendien is de taalondersteuning voor SharePoint Syntex voorlopig beperkt tot het Engels. Maar, Microsoft is duidelijk de ‘democratized AI’ weg ingeslagen en zal ongetwijfeld SharePoint Syntex verder ontwikkelen tot een breed bruikbaar product. Ondank deze beperkingen kunnen we vandaag al heel wat use cases dekken door de techniek.
In het laatste onderdeel gaan we dieper in op het Spikes tagging framework. Een generieke component die Spikes al bij verschillende klanten succesvol inzetten om in verschillende talen meer contextuele informatie te capteren.
De extra mile – Spikes tagging framework
Met Microsofts SharePoint Syntex werd een veelbelovende oplossing gelanceerd. De toepassing is echter nog beperkt als de documenten die je wil verwerken niet-Engelstalig zijn of de informatie die je wil ophalen moeilijker te vatten is in regels.
Net als Microsoft is Spikes de weg van de intelligente, slimme samenwerking ingeslagen en ontwikkelden wij een framework met een gelijkaardige doelstelling: het structureren van documenten om ze vlot opzoekbaar en inzetbaar te maken voor verschillende door kennis ondersteunde processen. Deze oplossing is van nature uit open en uitbreidbaar waardoor al een brede waaier aan documenten in verschillende industrieën succesvol verwerkt werden. Bovendien biedt het framework ondersteuning voor meerdere talen inclusief Nederlands, Frans en Engels.
Het platform beschikt naast de gebruikelijke vooraf getrainde AI algoritmen zoals sentiment analyse, topic mining, … ook over uitbreidingsmogelijkheden om op de markt beschikbare en zeer gespecialiseerde AI algoritmes of eigen AI modellen toe te passen. Daarnaast kan het systeem geïntegreerd worden met verschillende databronnen en kan het ook de verwerkte data aan verschillende platformen aanleveren.
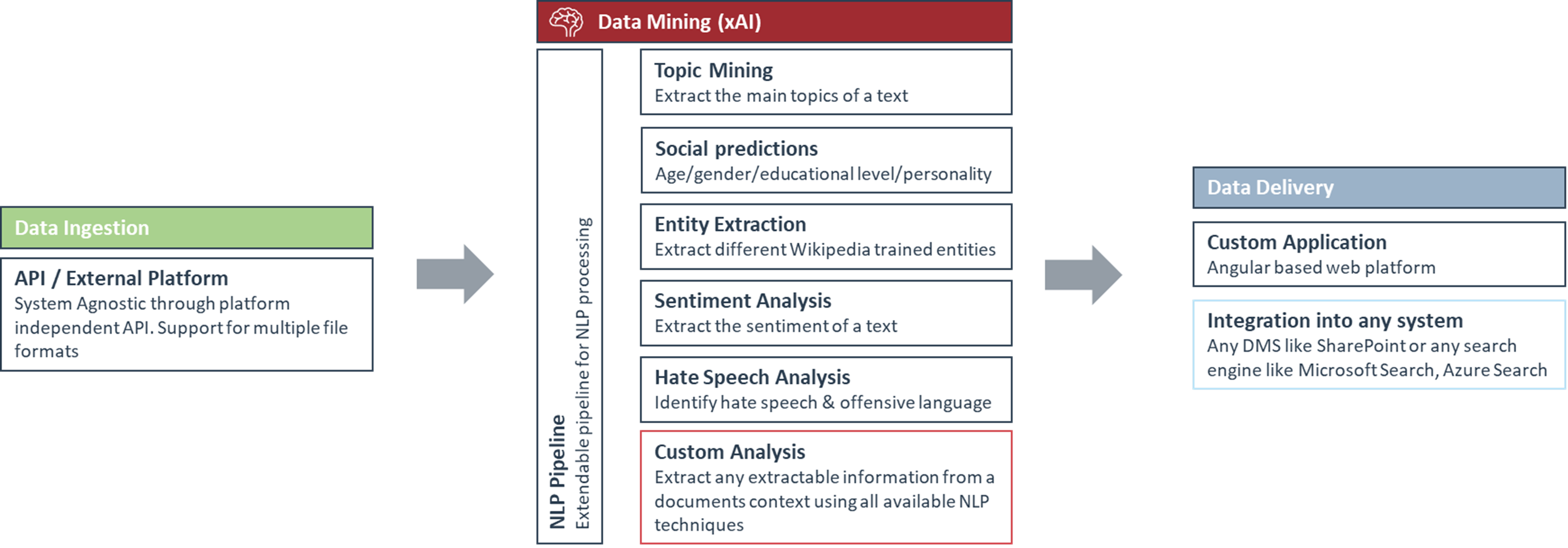
Figuur 6 – Bovenstaande afbeelding toont de tagging pipeline die Spikes opzet om ongestructureerde documenten te analyseren en te structureren op basis van elke beschikbare AI techniek.
Dat met het framework een enorm verscheiden set aan use cases afgedekt kan worden tonen we graag met enkele voorbeelden van succesvolle implementaties.
- Doorzoekbare recepturen: Voor een wereldspeler in de industriële bakkerij met verschillende lokale vertakkingen installeerden we het tagging framework om naast ingrediënten ook eigen productnamen, locaties, toepassingen (deeg, topping, …), … te herkennen. Daarnaast werden de recepturen ook automatisch als gluten of glutenvrij geclassificeerd.
- Automatisch aanbieden van relevante research: bij de ontginning van grondstoffen in mijnen worden enorm veel verschillende processen en technieken gebruikt op verschillende materialen. De research die hieromtrent wereldwijd verschijnt is dan ook zeer uitgebreid en divers. Om researchers niet te overladen met informatie, maar voor hen relevante kennis aan te bieden werden de research papers automatisch ontleed en werden processen, chemische componenten en technieken onttrokken aan de documenten.
Door de open implementatie van het platform zijn we ook niet gebonden aan één vast platform. Eens de kennis succesvol ontsloten werd, liggen alle opties open waaronder SharePoint waarbij de documenten voorzien worden van extra tags, bots die gebruik maken van Azure search in bijvoorbeeld Teams, eigen applicaties & mobiele toepassingen.
De dark data die omgezet werden tot meer gestructureerde informatie brengen natuurlijk pas op als ze ook slim ingezet worden. Pas dan maken ze de belofte van ‘smart’ data waar. In de blogreeks ‘De juiste informatie op het juiste moment’ gaan we dieper in op het contextueel aanbieden en toepassen van kennis op het juiste moment.
Slimme toepassingen om mensen met goesting te doen samen werken zit in ons DNA. Mocht je vragen hebben of graag eens jouw eigen use case voorleggen, aarzel dan niet ons te contacteren!

Ben Van Mol
Solution Architect
Benieuwd naar de verschillende mogelijkheden om kennis te organiseren binnen jouw organisatie? Herbekijk het webinar!
Meer informatie via onderstaande gele knop.


